1. 平均负载(Load Average)概念
1.1 单核 CPU 系统
单个 CPU 的处理能力和负载情况可以用下图表达,如果为1.0 表明负载已经饱和,CPU 没有更多的处理能力:
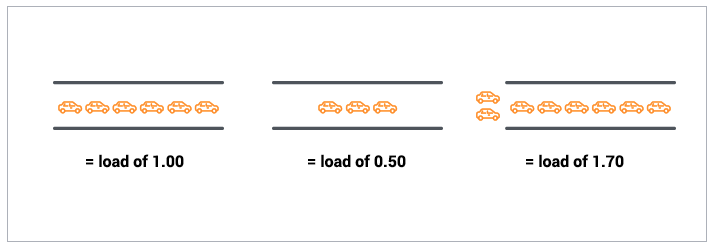
图中的卡车等同于 CPU 的时间片概念(一般情况下对应于需要处理的进程),Linux 称之为运行队列长度。
运行队列长度 = 正在运行的 + 等待运行条件的进程。
依照单核 CPU 的平均负载值含义,我们可以根据负载值采取对应的动作:
- 如果平均负载超过了 0.7,需要提前关注,最好在负载进一步上升之前处理掉;
- 如果平均负载已经超过了 1,那么需要立即介入处理;
1.2 多核 CPU 系统
多核与多处理器,基本上等同,但是还有些差别,因为涉及到涉及到缓存的数量,处理器之间的进程交接频率等等,一般情况下分析负载更多关注到核数。
有两个经验规则需要我们关注:
在多核系统中,负载是相对于可用的处理器核心数而言。获取主机 CPU 核数脚本如下:
1
|
$ grep -c 'model name' /proc/cpuinfo
|
2. Linux 平均负载
2.1 Unix 系统平均负载
Unix 系统中的平均负载表示了对于 CPU 的资源需求,通过汇总正在运行的线程数(使用率)和正在排队等待运行的线程数(饱和度)计算而出,主要是反映了等待运行线程对于 CPU 的资源诉求。
2.2 Linux 平均负载的异同点
但是,在 Linux 上的负载计算方式却有所不同,不再是简单的 CPU 运行队列的来体现负载,不再局限于 CPU 负载,而且系统层面平均负载的体现。
在 Linux 系统上平均负载包括了运行的进程和正在等待运行的进程,也包括了不可中断状态执行磁盘 I/O 的进程。这意味着在 Linux 上不能单用 CPU 余量或者饱和度,因为不能单从这个值来推断 CPU 或者磁盘负载。
Linux 系统中如果等待 IO 的进程多了,那么也会导致系统的平均负载升高,则是因为平均负载包含了 不可中断状态执行磁盘 I/O 的进程部分的原因。
Most UNIX systems count only processes in the running (on CPU) or runnable (waiting for CPU) states. However, Linux also includes processes in uninterruptible sleep states (usually waiting for disk activity), which can lead to markedly different results if many processes remain blocked in I/O due to a busy or stalled I/O system. 【2】
内核中的源码 v5.8.0 版本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
|
// kernel/sched/loadavg.c
/*
* Global load-average calculations
*
* We take a distributed and async approach to calculating the global load-avg
* in order to minimize overhead.
*
* The global load average is an exponentially decaying average of nr_running +
* nr_uninterruptible.
*
* Once every LOAD_FREQ:
*
* nr_active = 0;
* for_each_possible_cpu(cpu)
* nr_active += cpu_of(cpu)->nr_running + cpu_of(cpu)->nr_uninterruptible;
*
* avenrun[n] = avenrun[0] * exp_n + nr_active * (1 - exp_n)
*
* Due to a number of reasons the above turns in the mess below:
*
* - for_each_possible_cpu() is prohibitively expensive on machines with
* serious number of CPUs, therefore we need to take a distributed approach
* to calculating nr_active.
*
* \Sum_i x_i(t) = \Sum_i x_i(t) - x_i(t_0) | x_i(t_0) := 0
* = \Sum_i { \Sum_j=1 x_i(t_j) - x_i(t_j-1) }
*
* So assuming nr_active := 0 when we start out -- true per definition, we
* can simply take per-CPU deltas and fold those into a global accumulate
* to obtain the same result. See calc_load_fold_active().
*
* Furthermore, in order to avoid synchronizing all per-CPU delta folding
* across the machine, we assume 10 ticks is sufficient time for every
* CPU to have completed this task.
*
* This places an upper-bound on the IRQ-off latency of the machine. Then
* again, being late doesn't loose the delta, just wrecks the sample.
*
* - cpu_rq()->nr_uninterruptible isn't accurately tracked per-CPU because
* this would add another cross-CPU cacheline miss and atomic operation
* to the wakeup path. Instead we increment on whatever CPU the task ran
* when it went into uninterruptible state and decrement on whatever CPU
* did the wakeup. This means that only the sum of nr_uninterruptible over
* all CPUs yields the correct result.
*
* This covers the NO_HZ=n code, for extra head-aches, see the comment below.
*/
long calc_load_fold_active(struct rq *this_rq, long adjust)
{
long nr_active, delta = 0;
nr_active = this_rq->nr_running - adjust;
nr_active += (long)this_rq->nr_uninterruptible;
if (nr_active != this_rq->calc_load_active) {
delta = nr_active - this_rq->calc_load_active;
this_rq->calc_load_active = nr_active;
}
return delta;
}
|
2.3 平均负载命令行工具
相对于当前主机的 CPU 核数讲,Load 接近 CPU 核数或者超过 CPU 核数说明主机已经过载,进入到勉为其难的境界,特别当 Load 超过 CPU 核数以后,可能会带来程序的运行缓慢、服务响应延时增高、网络丢包或重传。
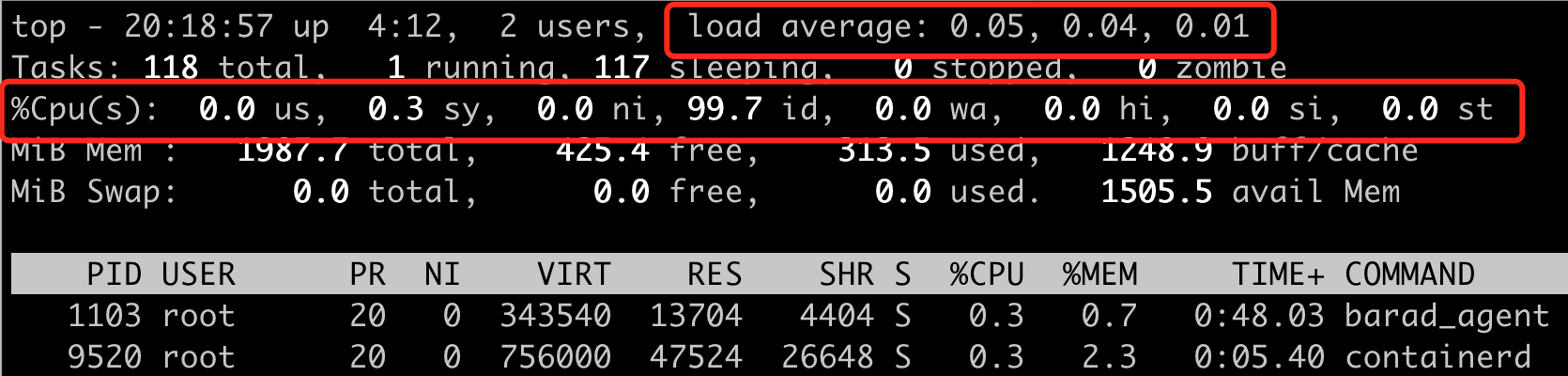
使用 uptime/top 命令可以很方便检查出主机的 load 情况,分为 load1,load5,load 15 三种,单位为分钟,分别代表最近 1 分钟、5 分钟、15 分钟的主机负载情况,一般情况下只是 load1 临时高,只是说明当前的负载临时有抖动,如果 load5、load15 也一直高的话,说明系统的负载在一定时间内进入高负载阶段。
%Cpu(s) 行,给了我们一个整体的 CPU 消耗的概览,其中:
- us 用户空间占用 CPU 百分比
- sy 内核空间占用CPU百分比
- ni 用户进程空间内改变过优先级的进程占用 CPU 百分比
- id 空闲 CPU 百分比
- wa io wait (disk)占用的 CPU 时间百分比
- hi 硬件中断
- si 软件中断
- st (steal time) 主要用于虚拟化环境,当管理程序为另一个处理器提供服务时,虚拟 cpu 在非自愿等待中的 CPU 时间(或)从虚拟机中窃取的CPU 时间百分比
vmstat 工具可以提供更多维度的负载情况分析,尤其是 system项中的 in 和 cs:
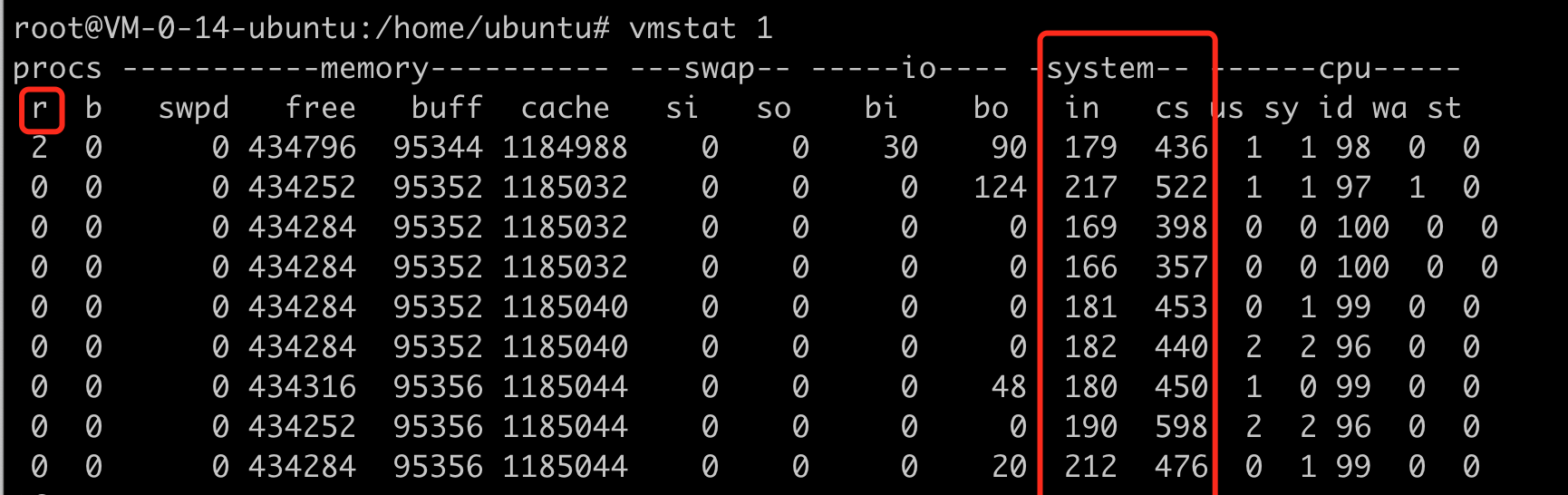
vmstat 从以下几个维度来提供更加细化的信息:
- procs
- r 表示足有等待的加上正在运行的线程数 【1】
- b 在uninterruptible 睡眠中的进程数
- mem
- swpd 以使用的swap空间
- free 剩余的物理内存
- buff buffer
- cache cache
- inact 非活动的内数量(-a选项)
- active 活动的内存的数量(-a选项)
- swap (一般容器环境下会自动关闭 swap)
- si 从磁盘交换的内存大小
- so 交换到磁盘的内存大小
- io
- bi 从块设备接收的块(block/s)
- bo 发送给块设备的块(block/s).如果这个值长期不为0,说明内存可能有问题,因为没有使用到缓存(当然,不排除直接I/O的情况,但是一般很少有直接I/O的)
- system
- in 每秒的中断次数,包括时钟中断
- cs 进程上下文切换次数,这个在 load 高的时候需要重点关注
- cpu 各个指标与 top 命令相同
3. 深入理解 Linux 平均负载
3.1 Linux 平均负载基础
1
2
3
4
5
6
7
|
$ cat /proc/loadavg
0.30 0.54 0.59 1/2411 20645
# load1 load5 load15 nr_running/nr_threads task_active_pid_ns
# nr_running 当前在各个 cpu 运行队列中的值, sum += foreach(cpu_rq(i)->nr_running)
# nr_threads 为 kernel/fork.c 文件中的全局变量,记录当前的整体线程数
# int nr_threads; /* The idle threads do not count.. */
# task_active_pid_ns 这个为当前活跃的进程的 ns 对应的一个索引位置
|
avenrun[0] 为 1 分钟负载,低 11 位保存了负载的小数部分,11位开始的高位保存了 load 的整数部分。
avenrun[1] 和 avenrun[2] 分别代表了 5 和 15 分钟。
include/linux/sched/loadavg.h [Linux v5.8.0],在线版:
1
2
3
4
5
6
7
|
#define FSHIFT 11 /* nr of bits of precision */
#define FIXED_1 (1<<FSHIFT) /* 1.0 as fixed-point */
#define LOAD_FREQ (5*HZ+1) /* 5 sec intervals */ // 每 5s 更新一次
#define EXP_1 1884 /* 1/exp(5sec/1min) as fixed-point */
#define EXP_5 2014 /* 1/exp(5sec/5min) */
#define EXP_15 2037 /* 1/exp(5sec/15min) */
|
fs/proc/loadavg.c,在线版:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
// From include/linux/sched/loadavg.h
#define LOAD_INT(x) ((x) >> FSHIFT) // 右移 11 位,得到整数部分
#define LOAD_FRAC(x) LOAD_INT(((x) & (FIXED_1-1)) * 100) // 首先获取到低的 11 位,然后乘以 100,
// 再右移 11 位置,得到最高的 2 位,舍弃了低位
// 对于读取 /proc/loadavg 文件的对外输出
static int loadavg_proc_show(struct seq_file *m, void *v)
{
unsigned long avnrun[3];
get_avenrun(avnrun, FIXED_1/200, 0);
// 函数运行后 avenrun[0] = avenrun[0]/(2^11) + 1/200
// FIXED_1/200在 这里是用于小数部分第三位的四舍五入,由于小数部分只取前两位
// LOAD_INT(a) = avenrun[0]/(2^11) + 1/200
// LOAD_FRAC(a) = ((avenrun[0]%(2^11) + 2^11/200) * 100) / (2^11)
// = (((avenrun[0]%(2^11)) * 100 + 2^10) / (2^11)
// = ((avenrun[0]%(2^11) * 100) / (2^11) + 1/2
seq_printf(m, "%lu.%02lu %lu.%02lu %lu.%02lu %ld/%d %d\n",
LOAD_INT(avnrun[0]), LOAD_FRAC(avnrun[0]),
LOAD_INT(avnrun[1]), LOAD_FRAC(avnrun[1]),
LOAD_INT(avnrun[2]), LOAD_FRAC(avnrun[2]),
nr_running(), nr_threads,
idr_get_cursor(&task_active_pid_ns(current)->idr) - 1);
return 0;
}
|
kernel/sched/core.c,在线版:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
/*
* nr_running and nr_context_switches:
*
* externally visible scheduler statistics: current number of runnable
* threads, total number of context switches performed since bootup.
*/
unsigned long nr_running(void)
{
unsigned long i, sum = 0;
for_each_online_cpu(i)
sum += cpu_rq(i)->nr_running;
return sum;
}
|
kernel/sched/loadavg.c ,在线版:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
|
// 获取负载的函数入口
/**
* get_avenrun - get the load average array
* @loads: pointer to dest load array
* @offset: offset to add
* @shift: shift count to shift the result left
*
* These values are estimates at best, so no need for locking.
*/
void get_avenrun(unsigned long *loads, unsigned long offset, int shift)
{
loads[0] = (avenrun[0] + offset) << shift;
loads[1] = (avenrun[1] + offset) << shift;
loads[2] = (avenrun[2] + offset) << shift;
}
// 计算 loadavg 的入口
/*
* a1 = a0 * e + a * (1 - e)
*
* a2 = a1 * e + a * (1 - e)
* = (a0 * e + a * (1 - e)) * e + a * (1 - e)
* = a0 * e^2 + a * (1 - e) * (1 + e)
*
* a3 = a2 * e + a * (1 - e)
* = (a0 * e^2 + a * (1 - e) * (1 + e)) * e + a * (1 - e)
* = a0 * e^3 + a * (1 - e) * (1 + e + e^2)
*
* ...
*
* an = a0 * e^n + a * (1 - e) * (1 + e + ... + e^n-1) [1]
* = a0 * e^n + a * (1 - e) * (1 - e^n)/(1 - e)
* = a0 * e^n + a * (1 - e^n)
*
* [1] application of the geometric series:
*
* n 1 - x^(n+1)
* S_n := \Sum x^i = -------------
* i=0 1 - x
*/
unsigned long
calc_load_n(unsigned long load, unsigned long exp,
unsigned long active, unsigned int n)
{
return calc_load(load, fixed_power_int(exp, FSHIFT, n), active);
}
|
include/linux/sched/loadavg.h
calc_load 为负载的计算函数,函数的公式为 a1 = a0 * e + a * (1 - e),在线版:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
/*
* a1 = a0 * e + a * (1 - e)
*/
static inline unsigned long
calc_load(unsigned long load, unsigned long exp, unsigned long active)
{
unsigned long newload;
newload = load * exp + active * (FIXED_1 - exp);
if (active >= load)
newload += FIXED_1-1;
return newload / FIXED_1;
}
|
依据这个公式进行推导:
$$
avenrun(t) = avenrun(t-1)*\frac{EXP_-N}{FIXED_-N} + n* \frac{FIXED1 - EXP_-N}{FIXED1}
$$
$$
= avenrun(t-1)*\frac{EXP_-N}{FIXED_-N} + n* ( 1-\frac{EXP_-N}{FIXED1})
$$
$$
如 e = \frac{EXP_-N}{FIXED_-N}
$$
$$
= avenrun(t-1)*e + n * (1-e)
$$
最后的汇总公式如下:
an = a0 * e^n + a * (1 - e) * (1 + e + ... + e^n-1) [1]
= a0 * e^n + a * (1 - e) * (1 - e^n)/(1 - e)
= a0 * e^n + a * (1 - e^n)
$$
S_n = \sum_{n=0}^{n}{x^i} = \frac{1-x^{n+1}}{1-x}
$$
#define EXP_1 1884 /* 1/exp(5sec/1min) as fixed-point */
#define EXP_5 2014 /* 1/exp(5sec/5min) */
#define EXP_15 2037 /* 1/exp(5sec/15min) */
当 N = 1 时候, e = 1884/2048 = 0.92 a(t) = a(t-1) * 0.92 + nr_active * 0.08
当 N = 5 时候,e = 2014/2048 = 0.98 a(t) = a(t-1) * 0.98 + nr_active * 0.02
当 N = 15 时候 e = 2037/2048 = 0.99 a(t) = a(t-1) * 0.99 + nr_active * 0.01
从上述也可以看出当前的运行进程数目 n 在负载的整体影响中的占比,1 分钟影响最大,15 分钟最小。
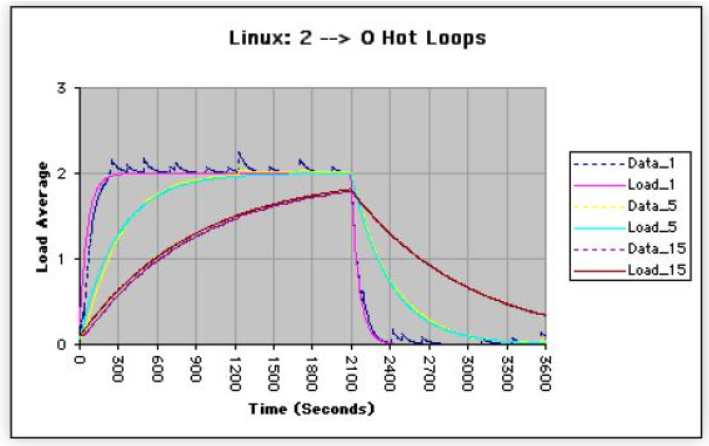
上图为在单核的 CPU 机器上,启动两个高负载(100%) 的后台程序进行测试,随后在 2100 秒处突然停止,此后的 1500秒(2100 - 3600) CPU 使用率为 0,结合上图我们可以得知:
1 分钟的样本跟踪速度最快,而 15 分钟的样本滞后最远。
对于 Load 有直接影响的就是 nr_active 的值。
3.2 串行计算版本
早期 Linux 内核版本 2.6.x 采用一个定时器触发函数 calc_load 中进行计算,实现简单粗暴,
kernel/timer.c 在线版:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
/*
* calc_load - given tick count, update the avenrun load estimates.
* This is called while holding a write_lock on xtime_lock.
*/
static inline void calc_load(unsigned long ticks)
{
unsigned long active_tasks; /* fixed-point */
static int count = LOAD_FREQ;
count -= ticks;
if (count < 0) {
count += LOAD_FREQ;
active_tasks = count_active_tasks();
CALC_LOAD(avenrun[0], EXP_1, active_tasks);
CALC_LOAD(avenrun[1], EXP_5, active_tasks);
CALC_LOAD(avenrun[2], EXP_15, active_tasks);
}
}
static unsigned long count_active_tasks(void)
{
return nr_active() * FIXED_1;
}
#define LOAD_FREQ (5*HZ) /* 5 sec intervals */
#define EXP_1 1884 /* 1/exp(5sec/1min) as fixed-point */
#define EXP_5 2014 /* 1/exp(5sec/5min) */
#define EXP_15 2037 /* 1/exp(5sec/15min) */
|
kernel/sched.c 文件对于每个 CPU 轮训计算 nr_active 值,在线版:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
unsigned long nr_active(void)
{
unsigned long i, running = 0, uninterruptible = 0;
for_each_online_cpu(i) {
running += cpu_rq(i)->nr_running; // 处于运行中的进程
uninterruptible += cpu_rq(i)->nr_uninterruptible; // 处于uninterruptible状态的进程
}
if (unlikely((long)uninterruptible < 0))
uninterruptible = 0;
return running + uninterruptible;
}
#define TASK_RUNNING 0
#define TASK_INTERRUPTIBLE 1
#define TASK_UNINTERRUPTIBLE 2
#define TASK_STOPPED 4
#define TASK_TRACED 8
/* in tsk->exit_state */
#define EXIT_ZOMBIE 16
#define EXIT_DEAD 32
/* in tsk->state again */
#define TASK_NONINTERACTIVE 64
|
在计算全局 Load 函数 calc_load 中,每 5s 需要遍历一次所有 CPU 的运行队列,获取对应 CPU 上的 Load。
尽管初看起来基于上述的计算方式,实现起来非常简单,但是定时进行各个处理器的串行计算,会涉及到 time 相关的 xtime_lock 全局锁,而且 CPU 的核数不固定,运行计算的时间也不固定,在核数特别多的情况下会造成 xtime_lock 获取的时间过长,可能导致在整个计算过程中的对系统带来延迟。
3.3 多核并行优化版 – per-CPU 负载计算
为了提升在多核并发系统中的阶段效率,nr_active 的计算会在 per-CPU 上进行定时计算,在整体计算负载的时间周期到来时,再统一汇总数据,通过读写分离提升了负载的计算效率。 而且全局 avenrun 的读和写之间也不需要专门的锁保护,可以将全局 Load 的更新和读进行分离。
优化的作者 Thomas 将定时器放到 sched_tick 中,每个 CPU 都设置一个 LOAD_FREQ 定时器。 定时周期到达时执行当前处理器上 Load 的计算。sched_tick 在每个 tick 到达时执行 一次,tick 到达是由硬件进行控制的,客观上不受系统运行状况的影响。但是为了保证在计算整体 load 计算的时候,所有的 per-CPU 都完成了计算,因此会在 LOAD_FREQ 的基础上延迟 10 tick,再统一计算整体负载。
单个 CPU 定期计算运行进程总数的函数演变成如下:
kernel/sched/loadavg.c [Linux 5.8.0],在线版:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// 计算的状态包括 this_rq->nr_running + this_rq->nr_uninterruptible
long calc_load_fold_active(struct rq *c, long adjust)
{
long nr_active, delta = 0;
nr_active = this_rq->nr_running - adjust;
nr_active += (long)this_rq->nr_uninterruptible;
if (nr_active != this_rq->calc_load_active) {
delta = nr_active - this_rq->calc_load_active;
this_rq->calc_load_active = nr_active;
}
return delta;
}
|
calc_global_load_tick 函数在 scheduler_tick 中定期更新当前 CPU 的运行的进程数量。
kernel/sched/loadavg.c,在线版:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
/*
* Called from scheduler_tick() to periodically update this CPU's
* active count.
*/
void calc_global_load_tick(struct rq *this_rq)
{
long delta;
if (time_before(jiffies, this_rq->calc_load_update))
return;
delta = calc_load_fold_active(this_rq, 0);
if (delta)
atomic_long_add(delta, &calc_load_tasks);
this_rq->calc_load_update += LOAD_FREQ;
}
|
kernel/time/timekeeping.c
计算全局的负载的触发定时器,在线版:
1
2
3
4
5
6
7
8
|
/*
* Must hold jiffies_lock
*/
void do_timer(unsigned long ticks)
{
jiffies_64 += ticks;
calc_global_load(ticks); // --> calc_global_load
}
|
kernel/sched/loadavg.c,在线版:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
/*
* calc_load - update the avenrun load estimates 10 ticks after the
* CPUs have updated calc_load_tasks.
*
* Called from the global timer code.
*/
void calc_global_load(unsigned long ticks)
{
unsigned long sample_window;
long active, delta;
sample_window = READ_ONCE(calc_load_update);
if (time_before(jiffies, sample_window + 10)) // 检查是否到了更新窗口,负载的计算必须在计算窗口的的 10 tick 以后,
// 这是为了保证所有的 CPU 的计算已经完成
return;
/*
* Fold the 'old' NO_HZ-delta to include all NO_HZ CPUs.
*/
delta = calc_load_nohz_read();
if (delta)
atomic_long_add(delta, &calc_load_tasks);
active = atomic_long_read(&calc_load_tasks); // 读取已经更新过的 active 值
active = active > 0 ? active * FIXED_1 : 0;
avenrun[0] = calc_load(avenrun[0], EXP_1, active);
avenrun[1] = calc_load(avenrun[1], EXP_5, active);
avenrun[2] = calc_load(avenrun[2], EXP_15, active);
WRITE_ONCE(calc_load_update, sample_window + LOAD_FREQ); // 添加为下一次更新的时间间隔 LOAD_FREQ = 5s
/*
* In case we went to NO_HZ for multiple LOAD_FREQ intervals
* catch up in bulk.
*/
calc_global_nohz();
}
|
per-CPU Load 的计算能够很好的分离全局 Load 的更新和读取,避免大型系统中 CPU 核数过多导致的 xtime_lock 问题。但是也同时带来了很多其他需要解决的问题。这其中最主要的问题就是 nohz 问题。
3.4 多核并行优化版 – nohz 问题优化
为避免 CPU 空闲状态时大量无意义的时钟中断,引入了 nohz 技术。在这种技术下,CPU 进入空闲状态之后会关闭该 CPU 对应的时钟中断,等 到下一个定时器到达,或者该 CPU 需要执行重新调度时再重新开启时钟中断。
CPU 进入 nohz 状态后该 CPU上的时钟 tick 停 止,导致 sched_tick 并非每个 tick 都会执行一次。这使得将 per-CPU 的 Load 计算放在 sched_tick 中并不能保证每个 LOAD_FREQ 都执行一次。如果在执行 per-CPU Load 计算时,当前 CPU 处于 nohz 状态,那么当前 CPU上的 sched_tick 就会错过,进而错过这次 Load 的更新,最终全局的 Load 计算不准确。
基于 Thomas 第一个 patch 的思想,可以在 CPU 调度 idle 时对 nohz 情况进行处理。采用的方式是在当前 CPU 进入 idle 前进行一次该CPU 上 Load 的更新,这样即便进入了 nohz 状态,该 CPU 上的 Load 也已经更新至最新状态,不会出现不更新的情况。
当然基于 nohz 的问题还是存在其他方式的问题需要优化,这里不再叙述,可参见这里。
4. 参考