1. Linux Load 负载高
在 Linux 系统上平均负载包括了运行的进程和正在等待运行的进程,也包括了不可中断状态执行磁盘 I/O 的进程( Uninterruptible Sleep))。这意味着在 Linux 上不能单用 CPU 余量或者饱和度,因为不能单从这个值来推断 CPU 或者磁盘负载。
Linux 系统中如果等待 IO 的进程多了,那么也会导致系统的平均负载升高,则是因为平均负载包含了不可中断状态( Uninterruptible Sleep)执行磁盘 I/O 的进程部分的原因,关于 Linux Load 统计方式深入分析参见这里。
进程一般是我们谈论用户空间来使用的,一个进程可能会有多个线程;在内核的调度层面来讲进程和线程没有区别,进程中的线程们,在内核中都是调度器独立的调度单元,而且 Load 的统计是在内核中基于线程进行统计的,因此在排查 Load 高的时候我们应该直接面向线程进行排查,如果是按照进程视图则会掩盖诸多的细节,更加详细的介绍参见这里。
1.1 Load 高问题分析
通过上述对于 Linux 系统平均负载的分析,我们可以得知对于 Load 产生影响的主要有以下两种情况:
- 系统中的活跃的进程较多,进程占用 CPU 资源高,可能导致频繁的切换, PS 状态为 R;
- 系统 CPU 使用率不高,Load 偏高,多数情况下是等待 Disk IO 的进程偏多导致,PS 状态为 D,代表不可中断 Uninterruptible Sleep (通常为 Disk IO)。
工欲善其事必先利其器,对于整体排查的工具我们使用 dstat。dstat 命令是一个用来替换 vmstat、iostat、netstat、nfsstat 和 ifstat 这些命令的工具,是一个全能系统信息统计工具,就像一个飞机仪表盘,能够将 cpu/disk/net/paging/system/procs/load 等整体展示。
1
2
3
4
5
|
$ sudo yum install -y dstat
$ dstat -cdngy -p --load --tcp
# 默认参数 dstat -cdngy,-p 包含进程的相关信息,--load 包含负载情况
# --tcp 包含 tcp 相关统计,包括(listen, established, syn, time_wait, close)
|
运行结果截图如下:
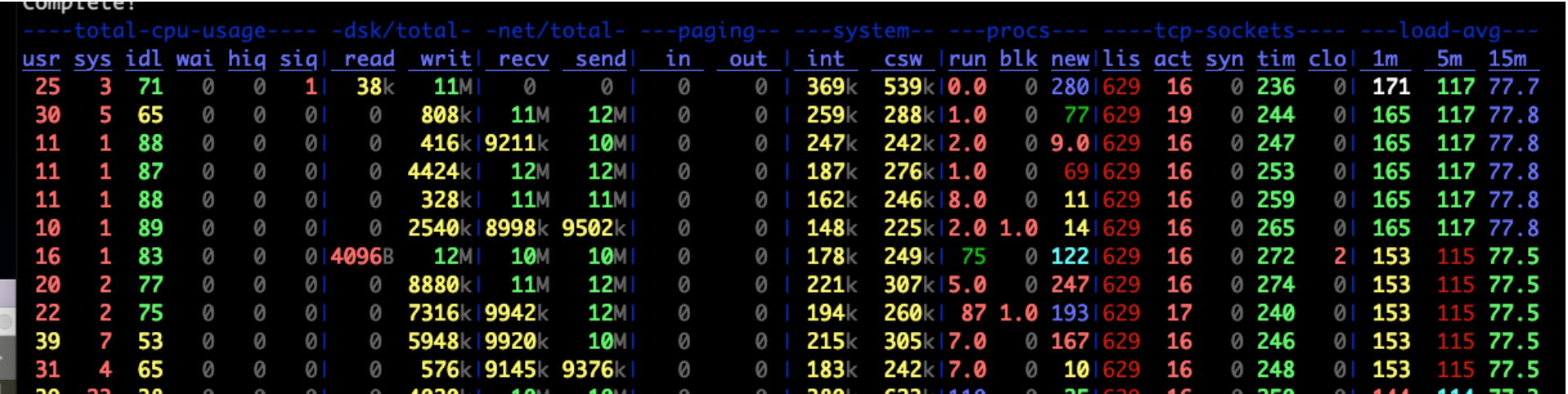
2. CPU 使用率低 Load 高场景测试
如果通过 top 或者 mpstat 查看系统的 CPU 使用率(包括 %si,%wa)都不高,通过 vmstat 查看系统 cs 也不高,但是系统的负载缺失居高不下,那么多半场景是有服务的进程或者线程陷入了 D 状态(即 Uninterruptible Sleep),特别是在程序对于外部存储 NFS Server 或者 Ceph 等存在依赖的场景中。
系统整体负载一栏推荐使用 dstat 查看。
处于 R 和 D 状态的线程是 Load 统计的需要来源,下面的脚本可以快速统计 R 和 D 状态的线程数目:
1
2
|
# 统计 R 和 D 状态的数目
$ ps -e -L h o state,cmd | awk '{if($1=="R"||$1=="D"){print $0}}' | sort | uniq -c | sort -k 1nr
|
更加详细的线程列表可以用以下脚本统计:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
#!/bin/bash
LANG=C
PATH=/sbin:/usr/sbin:/bin:/usr/bin
interval=5
length=86400
for i in $(seq 1 $(expr ${length} / ${interval}));do
date
LANG=C ps -eTo stat,pid,tid,ppid,comm --no-header | sed -e 's/^ \*//' | perl -nE 'chomp;say if (m!^\S*[RD]+\s*!)'
# LANG=C ps -eTo stat,pid,tid,ppid,comm --no-header | sed -e 's/^ \*//' | perl -nE 'chomp;say if (m!^\S*[RD]+\s*!)'|wc -l
date
cat /proc/loadavg
echo -e "\n"
sleep ${interval}
done
# R 代表运行中的队列,D 是不可中断的睡眠进程,一般为等待 disk io
|
这里我们使用两种情况来模拟产生 Uninterruptible Sleep 状态,并持续观察系统的 Load 负载情况。
2.1 神奇的 vfork
Linux 系统中也存在容易捕捉的 TASK_UNINTERRUPTIBLE 状态。执行 vfork 系统调用后,父进程将进入 TASK_UNINTERRUPTIBLE 状态,直到子进程调用 exit 或 exec(参见《神奇的vfork》)。
1
2
3
4
5
6
7
8
9
|
#include <sys/types.h>
#include <unistd.h>
void main() {
if (!vfork())
{
sleep(100);
}
}
|
使用 gcc 编译
1
|
$ gcc -o vfork_test vfork.c
|
然后我们写一个脚本产生 30 个 D 状态的进程,并观察系统的负载变化情况:
1
2
3
4
5
6
|
#!/bin/bash
for i in $(seq 1 30)
do
./vfork_test &
done
|
运行后使用查看进程脚本验证:
1
2
|
$ ps -e -L h o state,cmd | awk '{if($1=="R"||$1=="D"){print $0}}' | sort | uniq -c | sort -k 1nr
30 D ./vfork_test
|
我们使用 dstat 来查看系统负载:
1
2
3
4
5
6
7
8
9
10
|
# dstat -t -p --load
----system---- ---procs--- ---load-avg---
time |run blk new| 1m 5m 15m
30-11 10:52:29|0.0 0 34|28.4 13.2 5.22
30-11 10:52:30|1.0 0 172|28.4 13.2 5.22
30-11 10:52:31| 0 0 1.0|28.4 13.2 5.22
30-11 10:52:32| 0 0 1.0|28.5 13.5 5.36
30-11 10:52:33| 0 0 10|28.5 13.5 5.36
30-11 10:52:34|1.0 0 0|28.5 13.5 5.36
30-11 10:52:35| 0 0 1.0|28.5 13.5 5.36
|
我们可以看到负载在持续升高。通过监控的图可以很清楚反应出来,在 CPU 使用率和进程切换无明显变化的情况下,系统的负载一直持续升高,直至最后与 D 状态的进程数目相当,这是因为 Load 的计算公式是按照指数级别的衰减的,需要一定时间才能完全追随真实情况。
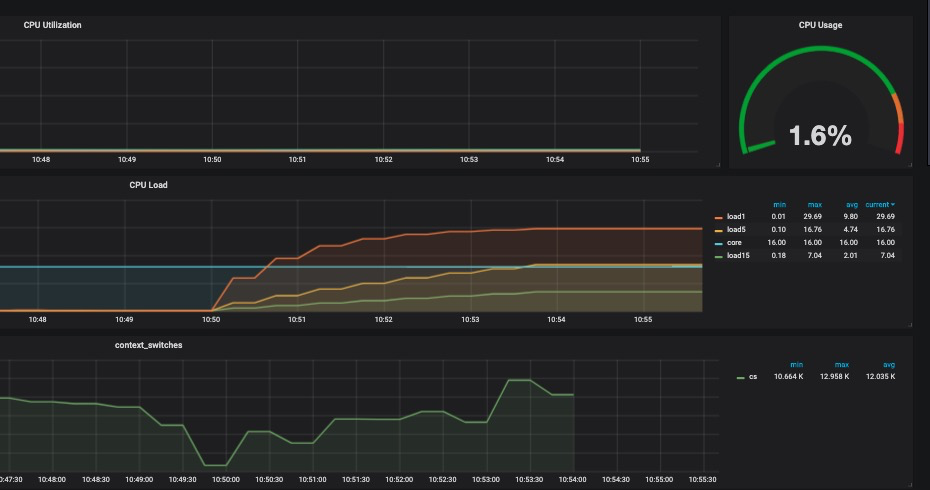
该程序测试完成后会产生不少僵尸进程,使用以下命令进行清理:
1
2
|
# 或者 killall vfork_test
$ ps aux|grep vfork_test|awk {'print $2'}|xargs kill -9
|
2.2 NFS 服务器停止服务
2.2.1 环境准备
为了模拟 NFS 服务器停止服务的情况下,,需要在准备一台服务器(既做客户端也做服务端),准备环境步骤如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
# 1. 安装 NFS 服务
# yum install nfs-utils -y
# systemctl start nfs
# systemctl start rpcbind
# 2. 创建 NFS 目录并设置共享
# mkdir /var/nfs
# chmod 755 /var/nfs/
# chown nfsnobody:nfsnobody /var/nfs/
# 3. 设置导出目录,以读写模式进行共享
# cat /etc/exports
/var/nfs *(rw,sync)
# exportfs -a
# 4. 确认共享情况并挂载
# showmount -e 172.16.18.161
Export list for 172.16.18.161:
/var/nfs *
# mkdir -p /mnt/nfs
# mount -t nfs 172.16.18.161:/var/nfs /mnt/nfs
# df
Filesystem 1K-blocks Used Available Use% Mounted on
172.16.18.161:/var/nfs 103080960 5168128 93493248 6% /mnt/nfs
|
2.2.2 停止 NFS Server 进程并测试
在停止 nfs 服务之前,进入到 NFS 挂载的目录 /mnt/nfs 下。
停止 NFS Server 进程服务:
在挂载的 /mnt/nfs 目录下执行一下脚本:
1
2
3
4
5
6
7
8
9
10
|
# cat /tmp/ls_nfs.sh
#!/bin/bash
for i in $(seq 1 30)
do
ls -hl &
done
# 位于 nfs 的挂载目录
[/mnt/nfs]# /tmp/ls_nfs.sh
|
验证查看:
1
2
3
4
5
6
7
8
9
10
11
12
13
|
$ ps -e -L h o state,cmd | awk '{if($1=="R"||$1=="D"){print $0}}' | sort | uniq -c | sort -k 1nr
30 D ls -hl
$ dstat -t -p --load
----system---- ---procs--- ---load-avg---
time |run blk new| 1m 5m 15m
30-11 11:55:34| 0 0 34|25.6 9.36 4.01
30-11 11:55:35|1.0 0 2.0|25.6 9.36 4.01
30-11 11:55:36|1.0 0 16|25.6 9.36 4.01
30-11 11:55:37|1.0 0 0|25.6 9.36 4.01
30-11 11:55:38| 0 0 9.0|26.1 9.72 4.16
30-11 11:55:39| 0 0 77|26.1 9.72 4.16
30-11 11:55:40| 0 0 5.0|26.1 9.72 4.16
|
通过监控查看:
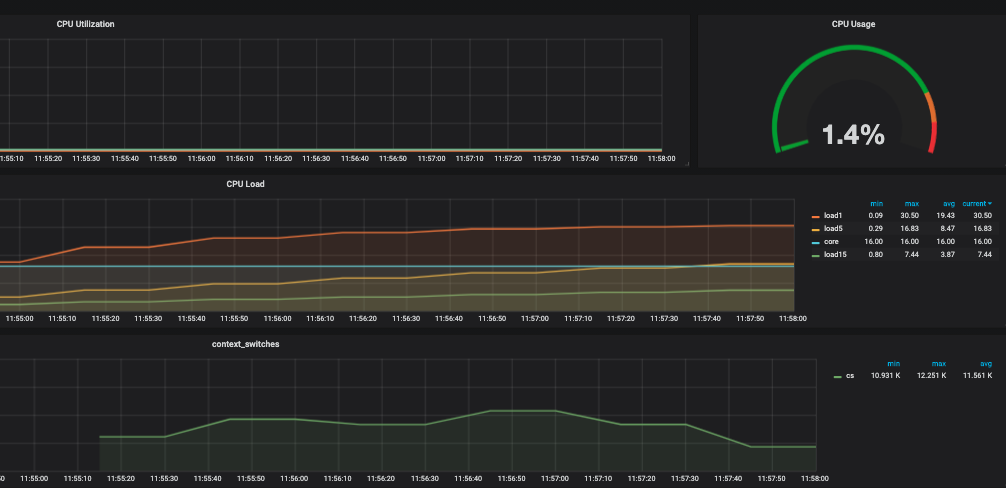
在测试完成后恢复通过启用 NFS Server 恢复:
1
2
|
# systemctl start nfs
# 或者强制卸载挂载 umount -lf /mnt/nfs
|
3. 参考